Using make to Orchestrate Machine Learning Tasks
One of the things we do at Datacratic is to use machine learning algorithms to optimize real-time bidding (RTB) policies for online display advertising. This means we train software models to predict, for example, the cost and the value of showing a given ad impression, and we then incorporate these prediction models into systems which make informed bidding decisions on behalf of our clients to show their ads to their potential customers.
The basic process of training a model is pretty simple: you show it a bunch of examples of whatever you want it to predict and apply whatever algorithm you've elected to use to set some internal parameters such that it's likely to give you the right output for that example. A trained model is basically set of parameters for whatever algorithm you're using. Once you've trained your model, you test it: show it a bunch of new examples, to see if the training actually succeeded at making it any good at outputting whatever it is you wanted it to. The testing step often results in some datasets which we can feed into our data visualization system.
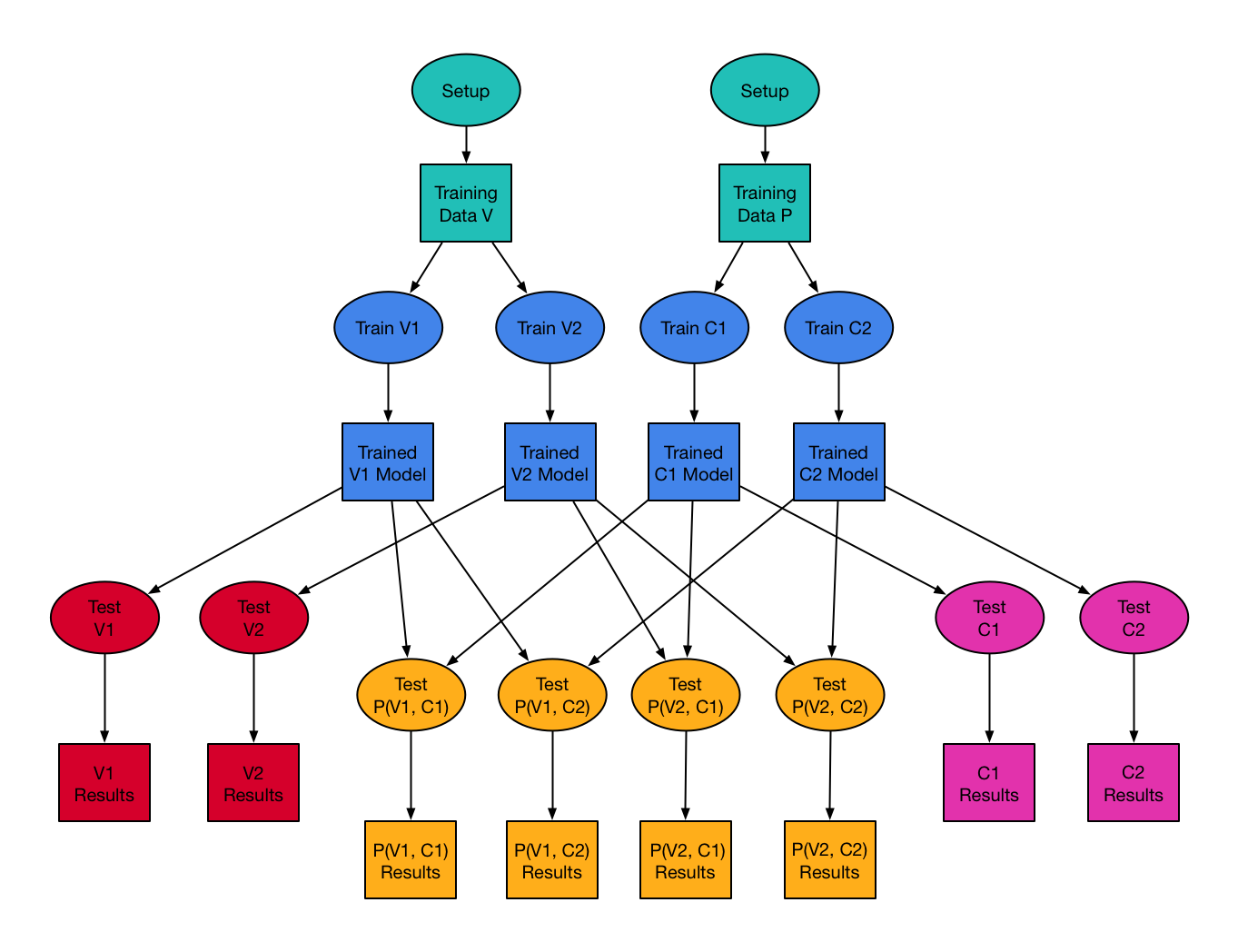
Now the bidding policies we've developed depend upon multiple such trained models, as mentioned above. Let's use the example of a policy P which depends on a value model V and a cost model C, so P(V,C). We won't need to train this policy per se, but we will want to run some simulations on it to test how good we would expect it to be at meeting our clients' advertising goals. We might come up with 2 different types of value models (say V1 and V2) and 2 different types of cost models (say C1 and C2) to train and test. So we end up with 4 possible combinations of value and cost models and thus 4 different possible policies to test: P(V1, C1), P(V1, C2), P(V2, C1), P(V2, C2). Note that in practice, we will likely come up with many more than 2 variations on value and cost models, but I'll use 2 of each to keep this example manageable.
So how do we actually go about doing all this testing and training efficiently, both from the point of view of the computer and the computer's operator (e.g. me)? When you're just training and testing models independently of each other, you can easily get by with a simple loop in a script of some kind: for each model, call train and test functions. When you have some second step that depends on combinations of models, like the situation described above, you can just add a second loop after the first one: for each valid combination, call test function. This is how we first built our training and testing systems, but then we decided to parallelize the process to take advantage of our 16-core development machine.
While brainstorming how we might build something which could manage the sequence of parallel jobs that would need to run, we realized that we'd already been using such a system throughout the development of these models: make. More specifically: make with the -j option for 'number of jobs to run simultaneously'. The make command basically tries to ensure that whatever file you've asked it to make exists and is up to date, first by recursively ensuring that all the files your file depends on also exist and are up to date, and then by executing some command you give it to create your file.
Casting our training/testing problem in terms of commands which make can understand is fairly simple and gives rise to the diagram at the top of this page: rectangles represent files on disk and ovals represent the processes which create those files. The only change required to our existing code was that the train and test functions had to be broken out into separate executable commands which read and write to files.
Why not just parallelize our simple for-loops using some threading/multiprocessing primitives? Because using those kinds of primitives can be difficult and frustrating, while using make is comparatively easy and gives us a number of other benefits. Beyond the aforementioned -j option which gives us parallelism, the -k option makes it less painful for some steps to error out without having to build any specific error-handling logic: make just keeps going with whatever doesn't depend on the failed targets. And when we fix the code that crashed and re-make, make can just pick up with those failed targets, because all the rest of the files on disk don't need to be updated and essentially act as a reusable cache or checkpoint for our computation (unless they caused the crash, at which point you delete them and make rebuilds them and keeps going).
Having named targets also makes it easy to ask make to just give us a subset of the test results: it automatically runs only what it needs to to generate those targets we ask for. When you invoke make, you have to tell it what to make, in terms of targets, for example 'make all_test_results' or 'make trained_model_V1' etc. Adding new steps, such as the ability to test multiple types of policies, for example, or a 'deploy to production' step, becomes fairly trivial. Finally, the decomposition of our code into separate executables was actually helpful in decoupling modules and encouraging a more maintainable architecture. And whenever we get around to buying/building a cluster (or spinning up a bunch of Amazon instances), we can just prefix our executable commands with whatever command causes them to be run on a remote machine! So, armed with our diagram, and our excitement about the benefits that using make would bring us, we implemented a script which essentially steps through the following pseudo-code, given a single master configuration file that defines the models to be used:
- for each command to be run (ovals in the diagram), generate a command-specific configuration file and write it to disk, unless an identical one is already there
- Setup, training and testing configuration files for V and C models
- Testing configuration files for P policies
- for each target (rectangles in the diagram), write to the makefile the command to run and the targets it depends on, adding the configuration file to the list of dependencies
- Setup targets for V and C models
- Training and testing targets for each V and C models
- Testing targets for policies P for each combination of V and C models
- call make, passing through whatever command-line arguments were given (e.g. -j8 -k targetName)
Step 1 is helpful in allowing us to change a few values in the master configuration file, and having make only rebuild the parts of the dependency tree that are affected, given that make rebuilds a target only if any of its dependencies have more recent file modification dates. This means that, for example, I can choose to change some value in the master configuration file related to the training of C models, and when I call make again, it will not retrain/retest any V models. Doing this in effect adds dependencies from the various commands to certain parts of the master configuration file and lets make figure out what work actually needs to be done. And, let it be said again: it will do everything in parallel! Unfortunately, I don't have any code to put up on GitHub yet as the script we wrote and I described above is very specific to our model implementation, but I wrote this all up to share our experiences with this structure and how pleased we are with the final result!
⁂