
Nicolas Kruchten
is a data visualization specialist
based in Montreal, Canada.
Machine Learning
Machine Learning is an artificial intelligence technique for getting computers to automatically program themselves to perform certain tasks. I studied this in my undergraduate years in the context of Intelligent Transportation Systems and worked extensively with these techniques during my time at Datacratic.
Data Visualization for Artificial Intelligence, and Vice Versa
Data visualization uses algorithms to create images from data so humans can understand and respond to that data more effectively. Artificial intelligence development is the quest for algorithms that can “understand” and respond to data the same was as a human can – or better. It might be tempting to think that the relationship between the two is that to the extent that AI development succeeds, datavis will become irrelevant. After all, will we need a speedometer to visualize how fast a car is going when it’s driving itself? Perhaps in some distant future, it might be the case that we delegate so much to AI systems that we lose the desire to understand the world for ourselves, but we are far from that dystopia today. As it stands, despite the name, AI development is still very much a human endeavour and AI developers make heavy use of data visualization, and on the other hand, AI techniques have the potential to transform how data visualization is done.
Machine Learning Meets Economics, Part 2
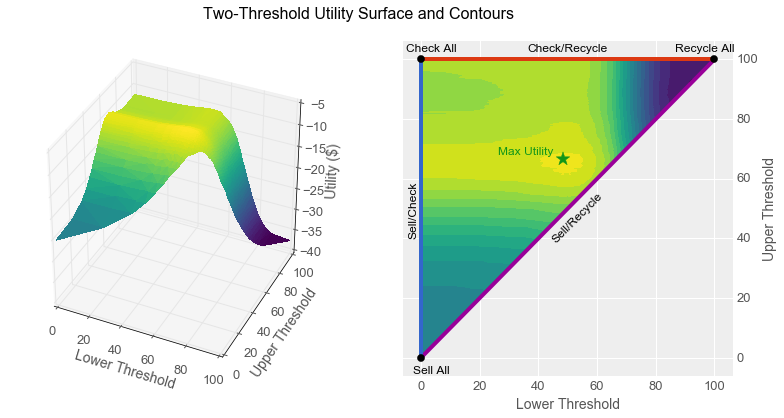
By using machine learning algorithms, we are increasingly able to use computers to perform intellectual tasks at a level approaching that of humans. Given that computers cost less than employees, many people are afraid that humans will therefore necessarily lose their jobs to computers. Contrary to this belief, in this article I show that even when a computer can perform a task more economically than a human, careful analysis suggests that humans and computers working together can sometimes yield even better business outcomes than simply replacing one with the other.
Specifically, I show how a classifier with a reject option can increase worker productivity for certain types of tasks, and I show how to construct and tune such a classifier from a simple scoring function by using two thresholds. I begin with a parable featuring the same characters as the one from Part 1 of this Machine Learning Meets Economics series. I recommend reading Part 1 first, as it sets up much of the terminology I use here.
Machine Learning Meets Economics
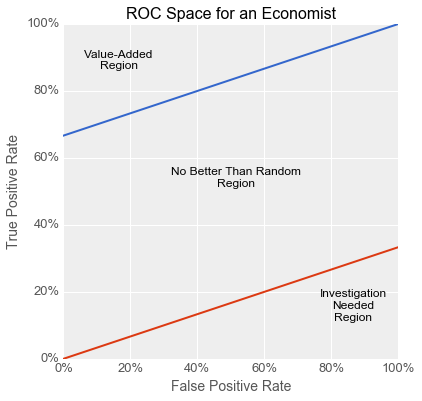
The business world is full of streams of items that need to be filtered or evaluated: parts on an assembly line, resumés in an application pile, emails in a delivery queue, transactions awaiting processing. Machine learning techniques are increasingly being used to make such processes more efficient: image processing to flag bad parts, text analysis to surface good candidates, spam filtering to sort email, fraud detection to lower transaction costs etc.
In this article, I show how you can take business factors into account when using machine learning to solve these kinds of problems with binary classifiers. Specifically, I show how the concept of expected utility from the field of economics maps onto the Receiver Operating Characteristic (ROC) space often used by machine learning practitioners to compare and evaluate models for binary classification. I begin with a parable illustrating the dangers of not taking such factors into account. This concrete story is followed by a more formal mathematical look at the use of indifference curves in ROC space to avoid this kind of problem and guide model development. I wrap up with some recommendations for successfully using binary classifiers to solve business problems.
Big Data Montreal: the Machine Learning Database
I was happy to oblige when I was invited to give a talk at Big Data Montreal about the project I work on at Datacratic: the Machine Learning Database (MLDB).
PAPIs.io 2014: Behind the scenes with a Predictive API
I gave a talk at in Barcelona at the PAPIs.io 2014 Predictive APIs conference last November.
Montreal Python: Unsupervised ML with scikit-learn
I gave a talk at Montreal Python on Data Science and Unsupervised Machine Learning with scikit-learn. The video is above and I posted all of my presentation materials online.
Visualizing High-Dimensional Data in the Browser with SVD, t-SNE and Three.js
Data visualization, by definition, involves making a two- or three-dimensional picture of data, so when the data being visualized inherently has many more dimensions than two or three, a big component of data visualization is dimensionality reduction. Dimensionality reduction is also often the first step in a big-data machine-learning pipeline, because most machine-learning algorithms suffer from the Curse of Dimensionality: more dimensions in the input means you need exponentially more training data to create a good model. Datacratic’s products operate on billions of data points (big data) in tens of thousands of dimensions (big problem), and in this post, we show off a proof of concept for interactively visualizing this kind of data in a browser, in 3D (of course, the images on the screen are two-dimensional but we use interactivity, motion and perspective to evoke a third dimension).
Big Data Week Montreal: From Big Data to Big Value
Video and slides from my talk at the kickoff of Big Data Week Montreal 2014.
Using make to Orchestrate Machine Learning Tasks
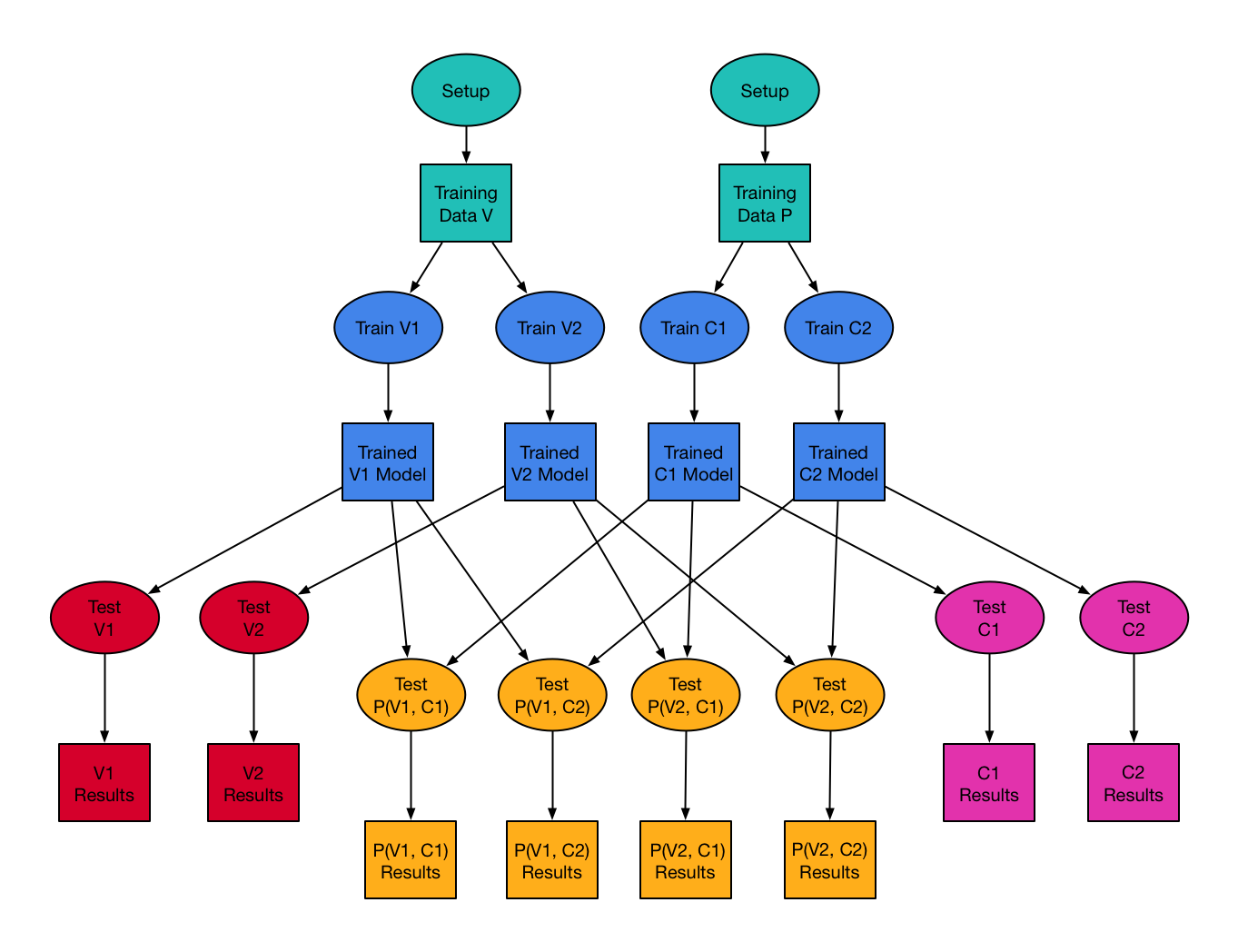
One of the things we do at Datacratic is to use machine learning algorithms to optimize real-time bidding (RTB) policies for online display advertising. This means we train software models to predict, for example, the cost and the value of showing a given ad impression, and we then incorporate these prediction models into systems which make informed bidding decisions on behalf of our clients to show their ads to their potential customers.